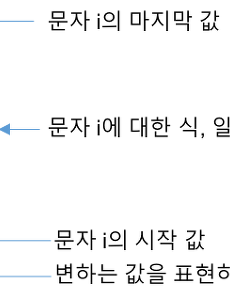
비용함수3 로지스틱회귀의 비용함수 이해 Logistic 회귀의 cost function 지금까지 해온 것 처럼 로지스틱회귀의 비용함수 역시 어설프나마 문돌이식 수학으로 이해해 보려고 했다. 그래서 일주일이 넘는 시간을 투자했으나 이번 시도는 앞선 시도들 보다 더 이해하기가 어려운 내용이었다. 때문에 이번 포스팅에서는 로지스틱회귀의 비용함수 이해에 필요한 몇가지 개념에 대한 설명과 지난 일주일간의 검색 과정에서 발견한 몇가지 팁을 설명하는 것 정도로 마무리 해야 할 것 같다. 몇 가지 개념 이미 많은 사람들이 알고 있다시피 기존 선형회귀에서 사용하던 비용함수를 로지스틱회귀에서 그대로 사용할 경우 그래프의 형태가 아래와 같이 표현된다고 한다(함수를 통해 아래 형태의 그래프를 그려보려고 무진 애를 썼으나 결국 실패했다). 선형회귀분석에서 이미 언급.. 2017. 5. 7. 수학 개념 정리 #2 - 시그마와 미분 머신러닝을 위한 기초 수학 #2지난 포스팅에서는 선형회귀분석의 가설 함수에 들어있는 개념인 기울기와 절편에 대해 알아보았다. 이번 포스팅에서는 비용함수와 관련하여 ∑ 연산과 제곱함수의 U자 형태 그래프로부터 경사하강법을 이용하여 비용의 최솟값을 찾아내는데 필요한 미분에 대해서 알아보도록 하자. ∑ 연산∑는 특정 범위 내에 있는 일련의 수들의 합을 표시하는 기호이다. 이 기호를 이용한 수식의 각 항을 보면 아래 그림과 같다. 시그마 기호를 기준으로 밑에는 변화하는 값을 표현할 문자(보통 i나 k를 사용)와 그 시작값을 등호로 연결하여 표시한다. 위 그림과 같이 i = 1이라고 표시하면 i라는 기호는 1부터 시작인 것이다. i = 10이라고 한다면 당연히 i가 10부터 시작된다는 의미이다. 다음으로 기호 위.. 2017. 2. 19. 선형회귀분석 함수 정리 선형회귀분석과 관련된 2가지 함수의 의미 정리이 글은 홍콩 과기대의 김성훈 교수님의 유튜브 강좌를 보고 제 나름대로 조금 더 이해를 하려고 풀어서 정리해본 글입니다.선형회귀분석 가설함수(Hypothesis function) 선형회귀분석의 기본적인 가설 함수 (Hypothesis function). 기존 데이터를 가장 잘 표현하는 직선을 결정하는 함수이며 이 직선은 W와 b를 변화시켜가면서 찾을 수 있다. 바로 이 최적의 W와 b를 찾는 것이 선형회귀분석의 목적이다. 그리고 이렇게 찾아진 W와 b를 함수에 대입하게 되면 기존의 데이터가 아닌 새로운 x값이 나타났을 때 그 새로운 x에 대한 y값을 예측할 수 있게 되는 것이다. 이 과정에서 가장 중요한 것은 기울기를 나타내는 W값이다. 즉, 전체적인 데이터가.. 2017. 2. 11. 이전 1 다음 반응형