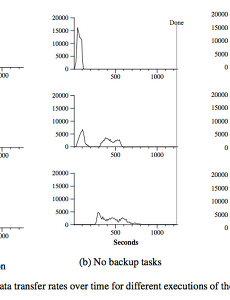
빅데이터29 [옛 글] [BigData] MapReduce - 성능 3 최초 작성일 : 2013/04/17 13:17 Effect of Backup Task Figure 3 (b)에서 우리는 backup task들이 비활성화된 정렬 프로그램의 실행을 볼 수있다.프로그램 실행의 흐름은 과도한 쓰기 작업이 있는 경우에 완료 시점까지 long tail 현상이나타난다는 것을 제외하면 Figure 3 (a)와 유사하다. 960초 이후 5개의 reduce task들을 제외한 모든 수행이 완료되었다. 그러나 이 마지막의straggler들은 이후 300초가 지날 때까지 끝나지 않았다. 모든 연산은 1283초가 걸렸으며소요시간이 44% 증가하였다. Machine Failure Figure 3 (c)에서는 연산 중에 1746개의 작업자를 제외한 200개의 작업자를 의도적으로몇분간 중지시킨 상.. 2013. 7. 19. [옛 글] [BigData] MapReduce - 성능 2 최초 작성일 : 2013/04/11 12:22 Sort sort 프로그램은 10의 10승개의 100바이트 크기 레코드들을 정렬한다.(약 1테라바이트의 데이터이다.)이 프로그램은 *TeraSort benchmark 이후에 모델링 되었다. 소팅 프로그램은 50 줄도 안되는 사용자 코드로 구성되어있다.3줄의 Map 함수는 text문서의 라인으로부터 10바이트의 정렬 키를 추출하고이 키와 원래 문서의 라인을 key/value 쌍으로 뽑아낸다. 우리는 라이브러리에 내장되어있는 Identity(항등)함수를 Reduce 연산자로 사용할 것이다.이 함수는 중간형태의 key/value 쌍을 아무 변화 없이 출력 key/value 쌍으로 보낸다.정렬된 최종 출력은 2방향으로 복제된 GFS 파일로 저장된다.(프로그램의 출력.. 2013. 7. 19. [옛 글] [BigData] MapReduce - 성능 1 최초 작성일 : 2013/03/26 12:54 2013. 7. 19. [옛 글] [잡설] 스마트폰은 작은 PC다... 최초 작성일 : 2013/03/20 12:54 먼저 관련 기사입니다.http://www.zdnet.co.kr/news/news_view.asp?artice_id=201303190829092010년에 처음 iOS 개발을 해보겠다고 다니던 회사를 그만 두고 공부를 시작했습니다.그리고 1년동안 허접한 앱 2개를 만들어 앱스토어에도 올려보고...2011년 5월부터 10월까지는 iOS 개발 프리랜서로 프로젝트 2개를 뛰었네요.그리고 2011년 11월 계속 프리를 할 것인지 다시 정규직으로 갈 것인지에 대해고민을 많이 했더랬죠.일단 정규직으로 가기로 한 후 구직을 시작했는데 그 때는 단지 iOS 개발에 국한시키지 않았습니다.그런데 그 당시 눈에 들어온 기업이 있었는데 넥스알이라는 하둡 전문 업체였습니다.솔직히 당시.. 2013. 7. 19. [옛 글] [BigData] MapReduce - 상세 기능 3 최초 작성일 : 2013/03/20 12:16 Status Information master는 내부에 HTTP 서버를 실행시켜 사용자가 볼 수 있도록 일련의 상태 정보 페이지를출력한다. 이 상태 페이지는 얼마나 많은 task가 완료 되었는지, 얼마나 많은 task가 수행 중인지,입력 바이트 수, 중간 데이터의 바이트 수, 출력 바이트 수, 처리율 등의 연산 수행에 대한진행 상태를 보여준다. 또한 이 페이지에는 표준 에러나 각각의 task에서 생성한 표준 출력 파일에 대한 링크도 제공한다. 사용자들은 이러한 데이터통해 연산이 얼마나 걸릴 지, 연산에 추가 리소스가 필요한지 예측할 수 있다.이 페이지들은 또한 예상했던 것 보다 더 느려지는 지점을 밝혀내는 데도 사용할 수 있다. 추가적으로 상위의 상태 페이지.. 2013. 7. 19. [옛 글] [BigData] MapReduce - 상세 기능 2 최초 작성일 : 2013/03/07 13:07 Input and Output type MapReduce 라이브러리는 몇가지 서로 다른 형식의 입력 파일을 읽을 수 있다.예를들면 "text"모드의 입력은 각각의 행이 key/value 쌍으로 취급된다. key는 파일상의위치(행)가 되고 value는 그 행의 내용이 되는 것이다.일반적으로 지원하는 또다른 형식은 일련의 key/value 쌍을 key로 정렬하여 저장한다. 각각의 입력 형식의 구현은 분산된 map task에서의 처리를 위해 어떤식으로 의미있는단위로 분할해야 하는가를 알고있다 (예를들면 text 모드에서는 행 단위로 영역이 구분되므로행 단위로 분할을 하게 되는 것이다). 대부분의 사용자들은 이미 정의된 소수의 입력 형식을 사용하겠지만 사용자들은 간.. 2013. 7. 19. [옛 글] [BigData] MapReduce - 상세 기능 1 최초 작성일 : 2013/02/26 12:58 Map과 Reduce 함수를 작성하는 기본 기능이 대부분의 필요를 충족시켜주기는 하지만 여기서 보다 확장된 유용한 기능들을 설명하고자 한다. Partitioning Function MapReduce의 사용자는 그들이 원하는 reduce task들과 출력 파일의 수를 ( R )과 같이 명시한다.Data들은 중간 key를 이용하는 partitioning 함수에 의해 이 task들 상호간에 분할된다. 기본적인 분할 함수는 해싱을 이용해 제공된다.(예를들면 "hash(key) mod R" 과 같은 형태다)이러한 분할 함수는 꽤 균형이 잘 잡힌 분할을 만들어낸다. 그러나 몇몇 경우에는 다른 함수들이 데이터를분할하는데 더 유용하다. 예를들면 때때로 출력된 key들은 U.. 2013. 7. 19. [옛 글] [BigData] MapReduce - Locality 등... 최초 작성일 : 2013/02/25 12:56 ================================================================== 내용이 어려워짐에 따라 번역은 점점 발번역으로 치닫고 있습니다...ㅠ.ㅠ첫 글에 링크해드린 원문 문서를 참조해서 보세요...================================================================== Locality(지역성) 네트워크 대역폭은 우리의 컴퓨팅 환경에서 비교적 부족한 자원이다.우리는 클러스터를 구성하고 있는 머신들의 로컬 디스크에 GFS(Google File System)에 의해관리되는 입력 데이터를 저장함으로써 네트워크 대역폭을 절약할 수있다. GFS는 각각의 파일을 64Mb의 블럭으.. 2013. 7. 19. [옛 글] [BigData] MapReduce - master data structure와 고장 허용 범위 최초 작성일 : 2013/02/14 14:49 ================================================================== 내용이 어려워짐에 따라 번역은 점점 발번역으로 치닫고 있습니다...ㅠ.ㅠ첫 글에 링크해드린 원문 문서를 참조해서 보세요...================================================================== Master Data Structure master 프로그램은 몇가지 데이터 구조를 유지한다. 각각의 map task와 reduce task에 대해master는 그 상태(비가동, 프로세스 진행 중 또는 완료)와 그 작업자 머신의 식별자를 저장한다.(유휴 작업이 없도록 하기 위해) master는 map .. 2013. 7. 19. 이전 1 2 3 4 다음 반응형