반응형
최초 작성일 : 2013/04/11 12:22
Sort
sort 프로그램은 10의 10승개의 100바이트 크기 레코드들을 정렬한다.(약 1테라바이트의 데이터이다.)
이 프로그램은 *TeraSort benchmark 이후에 모델링 되었다.
소팅 프로그램은 50 줄도 안되는 사용자 코드로 구성되어있다.
3줄의 Map 함수는 text문서의 라인으로부터 10바이트의 정렬 키를 추출하고
이 키와 원래 문서의 라인을 key/value 쌍으로 뽑아낸다.
우리는 라이브러리에 내장되어있는 Identity(항등)함수를 Reduce 연산자로 사용할 것이다.
이 함수는 중간형태의 key/value 쌍을 아무 변화 없이 출력 key/value 쌍으로 보낸다.
정렬된 최종 출력은 2방향으로 복제된 GFS 파일로 저장된다.
(프로그램의 출력 값으로 2테라바이트의 데이터가 작성된다.)
이전과 마찬가지로 입력 데이터는 64Mb 크기의 조각(M = 15000)으로 분할된다.
그리고 4000개(R = 4000)의 파일들에 정렬된 출력값들을 나누어 저장한다.
이 분할 함수는 데이터의 최초 바이트를 이용하여 분할된 R 중 하나에 출력값들을
나누어 넣게 된다.
이 벤치마크를 위한 분할 함수는 키 분산에 대한 지식 기반으로 만들어졌다.
우리가 MapReduce 수행의 전단계에 추가하려고 하는 일반적인 정렬 프로그램은
key들의 샘플을 모아서 마지막 정렬 단계를 위해 계산된 분할 포인트로 샘플 키들을
분산하는데 사용된다.

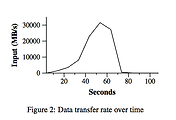
Figure 3의 (a)는 일반적인 정렬 프로그램의 실행을 보여준다.
좌측 상단이 그래프는 입력 값을 읽는 실행 속도를 보여준다.
실행 속도는 약 13 GB/s 정도에서 최고점에 이르렀다가 모든 map task가 종료 되기 전
200초 정도 지난 시점까지 상당히 빠르게 감소하다가 종료된다.
입력 값을 읽어들이는 실행 속도가 grep 함수 실행보다 짧다는 것에 주목하라.
이것은 정렬을 위한 map task들이 그들의 로컬 디스크에 중간 파일들을 저장하는데
절반 가량의 시간과 I/O 대역폭을 사용하기 때문이다.
grep을 위한 중간 형태의 출력 파일은 무시해되 될 정도의 크기이다.
좌측 중앙의 그래프는 데이터가 map task로부터 reduce task로 네트워크를 통해
전송되는 속도를 보여준다. 이 shuffling은 첫 번째 map task가 완료 되자마자 시작된다.
그래프에서 첫 번째로 높아진 부분은 약 1700여개의 reduce task들의 첫번째 배치 작업에 대한
값이다(전체 MapReduce는 약 1700여대의 머신들에 배치되어있고 각각의 머신은 한번에
최소한 1개의 reduce task를 실행한다).
연산이 진행되는 약 300초 동안 이 첫 번째 reduce task들의 배치 중 몇몇은 종료가 되고
남아있는 reduce task들을 위해 shuffling을 시작한다. 모든 shuffling은 약 600초 정도
연산을 수행한 후 완료된다.
좌측 하단의 그래프는 정렬된 데이터를 reduce task를 통해 최종 출력 파일에 저장하는 속도를 보여준다.
첫 shuffling이 끝나는 시점과 파일 기록 시점에는 지연이 발생하는데 이는 머신이 중간 데이터를
정렬하는데 부하가 걸리기 때문이다.
쓰기 작업은 잠시동안 약 2~4GB/s의 속도로 계속된다.
850초 무렵 정렬연산 내의 모든 쓰기 작업이 종료된다.
초기 기동시의 부하를 포함하여 전체 연산에는 891초가 소요되었다.
이 것은 현재까지 보고된 TeraSort 벤치마크의 가장 좋은 기록인 1057초와 근접한 값이다.
알아두어야 할 몇가지 사항은 우리의 로컬 최적화를 통해 대부분의 데이터가 비교적 제약이 있는
네트워크를 우회하여 로컬에서 읽혀지기 때문에 입력 속도는 shuffle 속도나 출력 속도보다 빠르다는
것이다. shuffle 속도는 출력 속도보다 빠른데 이는 출력 단계에서는 정렬된 데이터를 복사하여
2벌의 데이터를 기록하기 때문이다(우리는 신뢰성과 가용성을 높이기 위해 출력 데이터의 복제본을
만든다). 우리는 2개의 복제된 데이터를 기록하는데 이는 신뢰성과 가용성이 우리의 기반
파일시스템으로부터 제공받도록 만들어진 메커니즘 때문이다.
복제가 아닌 삭제 기능의 코드를 사용할 경우 데이터 기록을 위한 네트워크 대역폭에 대한 요구는
더욱 감소한다.
*TeraSort benchmark
Jim Gray. Sort benchmark home page.
http://research.microsoft.com/barc/SortBenchmark/.
반응형
'Study > 빅데이터' 카테고리의 다른 글
| [옛 글] [BigData] MapReduce - 경험 (0) | 2013.07.19 |
|---|---|
| [옛 글] [BigData] MapReduce - 성능 3 (0) | 2013.07.19 |
| [옛 글] [BigData] MapReduce - 성능 1 (0) | 2013.07.19 |
| [옛 글] [BigData] MapReduce - 상세 기능 3 (0) | 2013.07.19 |
| [옛 글] [BigData] MapReduce - 상세 기능 2 (0) | 2013.07.19 |