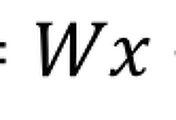선형회귀분석 - 문돌이 식으로 해석하기~
지난 번 Docker를 이용하여 텐서플로우를 설치해보았다. 일단 설치는 잘 되었고 부수적으로 Jupyter라는
웹 기반의 Python IDE도 알게 되었다. 그리고 일단 설치를 했으니 공부좀 해보자 하는 마음에 책을 한 권
e-Book으로 구매했다. “텐서플로우 첫걸음(조르디 토레스 지음, 박해선 옮김, 한빛미디어 출판)”이라는
책이었다. 0장 한국어판 서문과 1장 텐서플로우 기본 다지기를 어렵지 않게 넘기고 드디어 2장 에 다다르게
되었다. 2장의 내용은 텐서플로우를 이용하여 선형회귀분석을 하는 것이다.
선형회귀분석…선형…직진하다가…회귀…유턴하는건가…-.-?
아무튼 AI에 관심을 가지면서 많이 들어보던 용어인데 사실 수학 용어에 알러지 반응이 있어 이런 용어들이
나오면 무의식적으로 워프를 해버린다…-.- 그래도 본격적으로 공부를 해보기로 했으니 이제는 그러면
안될 것 같아 조금 자세히 들여다 보려는데…아무래도 텐서플로우 입문서이다보니 설명이 매우 간략하다.
그리고 뒤에서 말해주겠다고 약올리는 부분도 있고…
애초에 어려운 알고리즘에 대한 내용은 우선 피하고 텐서플로우 자체에 대해 알아보자고 계획을 잡았지만
이놈에 호기심이란…내가 만일 판도라였다면 제우스 면전에서 상자를 열어재꼈을 것이다…-.-
그래서…지난 1주일 내내 도대체 선형회귀분석이 뭔지 알아보느라 시간을 보냈다. 그 것을 이번 포스팅에
정리해보고자 한다. 물론 문돌이의 정리이기에 어디로 튈지는 장담 못한다…ㅠ.ㅠ
Jupyter부터…
지난 시간에 다음에는 Jupyter를 좀 알아보자고 했었는데…사실 Jupyter는 IDE 툴이라서 사용법 외에
특별히 설명할 만한 것이 없는 것 같다. 우선 Jupyter 공식 홈페이지와 사용법을 비교적 잘 설명한 블로그
하나를 링크하는 것으로 대신하고 본문 내용 중에 예제 업로드 하는 방법 정도 설명하겠다.
Jupyter 공식 홈페이지 : http://jupyter.org
옥수별님 블로그 : http://sams.epaiai.com/220763757405
예제 업로드 하기
우선 시간 절약을 위해 텐서플로우 첫걸음의 제 2장 예제를 Jupyter에 업로드 하도록 하겠다.
원 저자의 소스도 있지만 번역을 하신 박해선 님의 소스가 좀 더 깔끔하고 Jupyter Notebook
으로 설명도 곁들여져 있어 공부하기 좋다.
소스 link : https://github.com/rickiepark/first-steps-with-tensorflow
아래와 같은 과정으로 Jupyter에 소스를 업로드 하자.
- Jupyter Notebook 목록 우측 상단에 있는 Upload 버튼을 클릭한다.
- 파일 선택 창이 나오면 소스코드를 다운로드 받은 위치로 이동하여 선형회귀분석 소스인
chapter2_regression.py.ipynb를 선택하고 선택 버튼을 누른다.
- Notebook 목록에 방금 올린 소스 파일명이 가장 위에 보여지면 그 오른쪽의 파란색 Upload
버튼을 한 번 더 눌러준다. - 소스 파일의 업로드가 완료되면 아래 그림처럼 기존의 다른 Notebook들과 같은 형태로
표시된다. - chapter2_regression.py.ipynb를 클릭하면 드디어 소스를 조작할 수 있는 Notebook
화면이 등장한다.





선형회귀분석 간단 정리
우선 가장 단순하게 시작을 해보도록 하자. 우선 아래 2가지만 알고 가도록 하자.
- 한 변수(y, 종속 변수)가 다른 변수(x, 독립 변수)에 의해 어떻게 영향을 받는지 분석한다.
즉, 두 변수간에 인과관계가 있을 때 유효하다. (예 : 소득 수준과 문화 생활에 지출하는 비용간의 관계) - 선형회귀 모델을 표현하는 함수는 y = W * x + b이다.
일단 종속 변수에 대해 독립 변수가 1개인 것을 단순 선형회귀라고 하며 오늘은 이 단순 선형회귀만
다룬다. 선형 회귀라는 이름에서 ‘선형’이 의미하는 것은 분석의 결과가 직선의 형태를 띠고 있기 때문이다.
(회귀라는 용어에 대해서는 다음 링크 참조 :
http://terms.naver.com/entry.nhn?docId=1625383&cid=42251&categoryId=42262)
이 것은 두 번째 적은 함수에서도 알 수 있다. 바로 W라는 기울기와 b라는 y절편을 갖는 1차방정식이다.
이는 좌표 평면상에서 직선을 표현하게 된다.
이러한 기본 지식을 가지고 선형회귀분석을 간단하게 요약 설명하면 과거의 데이터를 통해 선형회귀 모델
방정식을 가장 잘 표현하는 W값과 b값을 찾고 이렇게 찾은 W값과 b값을 방정식에 대입하게 되면 나중에
새로운 x가 발견되었을 때 이 방정식을 통해 y의 값을 추측해낼 수 있는 것이다. 또 다른 측면에서는
y와 x가 관계가 있는지 없는지, 관계가 있다면 얼마나 있는지를 확인하는 목적에도 사용될 수 있다.
아래 우측 그림과 같은 그래프로 표현되는 데이터 집단이 있다면 이 그래프를 가장 잘 표현하는 직선은
오른쪽 그림의 파란 선이 될 것이다. 바로 이 파란 선을 만들 수 있는 W와 b의 값을 찾는 것이 1차 목적이다.
(아래 그림은 텐서플로우 첫걸음의 예제로부터 가져온 것이다.)
 |  |
실제로 해보기
설명을 하고나서도 뭔소린지 당췌 모르겠다…ㅠ.ㅠ 게다가 예제에서는 아무런 의미도 없는 난수를
통해 생성한 데이터를 가지고 설명을 하니 왜 이런 짓거리를 해야 하는건가 하는 생각조차 든다.
그러니 실생활에서 접할 수 있는 데이터를 가지고 한 번 진행을 해보자
집고 넘어가자!
구글이 텐서플로우같은 훌륭한 라이브러리를 공개하는 것에 대해 매체에서 언급하는 내용 중 2가지만
짚어보자
- 알고리즘이나 툴 자체보다는 데이터가 더 중요하다.
- 세상에는 많은 업무 분야들이 있고 아무리 구글같은 회사라 하더라도 그 모든 분야를 모두 아우를
수는 없다. 따라서 각 분야의 전문가들이 텐서플로우를 어떻게 이용하는지 알 수 있는 기회가 된다.
이 이야기가 선뜻 와 닿지 않았는데 이번에 ‘실생활에서 접할 수 있는 자료로 공부해보자’라고 생각하고
진행하는 과정에서 뼈저리게 느꼈다. 적절한 데이터를 찾는 작업이 결코 만만한 작업이 아니었다.
실제로 데이터 사이언티스트들이 이런 일을 하는지는 모르겠지만 분석이 필요한 데이터를 발굴하고
이 데이터사이의 연관성을 찾아내는 작업이 얼마나 어려운 일인지를 새삼 깨다았다.
실생활에서 접할 수 있는 데이터를 찾기 위해 우선 생각한 것이 공공데이터 포털이었다. 사실 일주일 동안
가장 시간을 많이 들인 것이 이 공공데이터 포탈에서 분석이 가능할만한 데이터, 인과관계가 있을 법한
데이터를 찾는 일이었다. 결과부터 말하면 결국 찾지 못했다. 독립 변수로 쓸 데이터와 종속 변수로 쓸
데이터를 찾아야 하는데 시계열의 범위가 맞지 않거나 아예 시계열 데이터가 없거나 한 것들이 많았다.
일단 ‘서울특별시 사회인식 통계’라는 항목에서 몇가지 자료를 추출했지만 겨우 시계열 범위가 일치할
뿐, 구별로 분산된 데이터인데다가 얼핏 봐도 하나의 독립 변수로는 설명이 되지 않는 그런 데이터였다.
그래서…엉망이나마 이번에 사용할 데이터는 아래 2개의 데이터인데 앞서 말한 바와 같이 구별로
측정된 데이터를 구분없이 하나로 통합해서 사용하였다.
‘서울시 소득대비 부채현황 통계’
 서울시 소득대비 부채현황 통계.xls
서울시 소득대비 부채현황 통계.xls‘서울시 시민행복지수 통계’
생각보다 글이 길어져 본격적인 분석은 다음 글에 이어서 하도록 하겠습니다~
'Study > 인공지능학습' 카테고리의 다른 글
| 수학 개념 정리 #2 - 시그마와 미분 (4) | 2017.02.19 |
|---|---|
| 수학 개념 정리 - 기울기와 절편 (2) | 2017.02.18 |
| 선형회귀분석 함수 정리 (0) | 2017.02.11 |
| TensorFlow(텐서플로우) 살펴보기 - 3 (0) | 2017.02.04 |
| [TensorFlow] Docker image로 설치해보기~ (0) | 2017.01.07 |