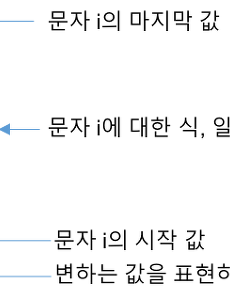
미분2 자연로그와 자연상수 e 심화학습 자연로그! 너 죽고 나 죽자! - 고등 수학을 초등학생처럼 배워보기~ 지난 글에서 내가 문돌이라는 것을 무기 삼아 겨우 자연상수 설명 조금하고 자연로그는 그저 그런게 있는갑다 하고 그냥 넘어가버렸다. 하지만 역시…뒤처리가 안된 것 마냥 여전히 찜찜하기 그지없다. 그래서 한 번 더 자연로그를 이해하는데 도전해보기로 하였다. 과연 잘 설명이 될 지는 모르겠으나 이미 언급한 바와 같이 이러한 과정 하나하나가 분명 앞으로 나아가는 길이라 믿는다. 문돌이 혹은 수포자의 한계 어떤 수학 공식을 풀이 한다는 것, 왜 그런 공식이 도출 되었나 하는 것은 곧 수학의 입장에서는 검증을 하는 것, 다시 말해 ‘증명’을 하는 것이다. 그런데 아이러니컬 하게도 증명을 하게 되면 처음의 단순했던 식이 매우 복잡해진다. 이것은 문.. 2017. 3. 25. 수학 개념 정리 #2 - 시그마와 미분 머신러닝을 위한 기초 수학 #2지난 포스팅에서는 선형회귀분석의 가설 함수에 들어있는 개념인 기울기와 절편에 대해 알아보았다. 이번 포스팅에서는 비용함수와 관련하여 ∑ 연산과 제곱함수의 U자 형태 그래프로부터 경사하강법을 이용하여 비용의 최솟값을 찾아내는데 필요한 미분에 대해서 알아보도록 하자. ∑ 연산∑는 특정 범위 내에 있는 일련의 수들의 합을 표시하는 기호이다. 이 기호를 이용한 수식의 각 항을 보면 아래 그림과 같다. 시그마 기호를 기준으로 밑에는 변화하는 값을 표현할 문자(보통 i나 k를 사용)와 그 시작값을 등호로 연결하여 표시한다. 위 그림과 같이 i = 1이라고 표시하면 i라는 기호는 1부터 시작인 것이다. i = 10이라고 한다면 당연히 i가 10부터 시작된다는 의미이다. 다음으로 기호 위.. 2017. 2. 19. 이전 1 다음 반응형