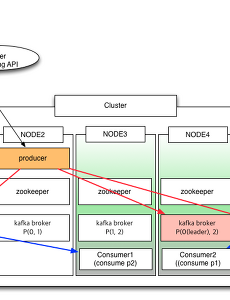
카프카8 Cluster : The Beginning - Apache Kafka와 EMQ 연동 목차 1. Cluster : The Beginning - Hadoop, HBase 그리고 Kafka 2. Cluster : The Beginning - Raspberry pi에 MQTT (EMQ) 설치하기 3. Cluster : The Beginning - Raspberry pi에 HAProxy 설치하기 4. Cluster : The Beginning - Raspberry pi에 Apache Kafka 설치하기 5. Cluster : The Beginning - Apache Kafka와 EMQ 연동(이번 글) 6. Cluster : The Beginning - Hadoop 2.9.0 설치 7. Cluster : The Beginning - HBase 1.2.6 설치 8. Cluster : The Begi.. 2018. 1. 3. Cluster : The Beginning - Raspberry pi에 Apache Kafka 설치하기 목차 1. Cluster : The Beginning - Hadoop, HBase 그리고 Kafka 2. Cluster : The Beginning - Raspberry pi에 MQTT (EMQ) 설치하기 3. Cluster : The Beginning - Raspberry pi에 HAProxy 설치하기 4. Cluster : The Beginning - Raspberry pi에 Apache Kafka 설치하기 (이번 글) 5. Cluster : The Beginning - Apache Kafka와 EMQ 연동 6. Cluster : The Beginning - Hadoop 2.9.0 설치 7. Cluster : The Beginning - HBase 1.2.6 설치 8. Cluster : The Beg.. 2017. 12. 25. [간보기 | Kafka] 정리를 마치며 Kafka 정리를 마치며분산 시스템 관리의 어려움 얼추 node 모듈을 이용한 kafka 서비스가 구현이 된 것 같았다. 트위터 Streaming API를 이용하여 데이터를 잘 가져오고, producer는 이 데이터를 broker에게 잘 전달하고, consumer는 broker로부터 데이터를 잘 가져와 로그를 뿌려주고… 하지만 어느 순간 이러한 프로세스가 중지되어있기 일쑤였다. zookeeper쪽이나 kafka쪽이나 서버 콘솔에 출력되는 로그는 대체로 네트워크가 끊겼다는 메시지인데 도대체 이 문제가 어떤 원인으로 발생하는 지를 알 수가 없는 것이다. 애초에 분산 시스템에서 장애의 원인을 찾는 것은 매우 어려운 일이라는 것은 알고 있었지만 아무리 작은 클러스터라도 이 문제를 직접 겪으니 참 답이 안나온다... 2016. 5. 20. [간보기 | kafka] 쉬어가자 - 소스 정리와 모니터링 툴 소스 정리와 모니터링 툴소스 정리일단 급하게 기능을 확인하다보니 소스 코드가 엉망이다. 조금이나마 다듬어야 보기가 편할 것 같아 쉬어갈 겸 우선 node 소스들을 정리했다. tmgetter.js (트위터 메시지를 받아서 콜백 함수를 통해 topic으로 메시지를 보내는 모듈)var Twitter = require('twitter'); var count = 0; var client = new Twitter({ consumer_key: '...', consumer_secret: '...', access_token_key: '...', access_token_secret: '...', }); var msgArr = new Array(); /** * parameter * msgCount : kafka 토픽으로 보.. 2016. 4. 30. [간보기 | Kafka] Kafka 무작정 실행하기 - 2 Kafka 무작정 실행하기 - 258의 비밀 먼저 지난 번 마지막에 언급했던 58이란 숫자의 비밀을 밝혀보자. 사실 정확한 원인은 아직 확인 못했다. 다만 지난 번 코드의 구현이 ’트위터 메시지가 하나 들어올 때마다 producer 하나를 만들어 트위터 메시지를 topic에 보낸다’는 것이었다. 이 과정에서 의심할 수 있는 것은 매번 producer를 만들어 커넥션울 하게 되니 아마도 이 커넥션 수에 제한이 걸려버린 것이 아닐까 하는 부분이었다. 그래서 일단 직감에 의존해 producer에서 topic으로 메시지를 보낸 후 API의 close 함수로 연결을 끊어보았다. 예상이 적중하였는지 이후로는 58개의 제한에 걸리지 않고 트위터에서 받아오는 모든 메시지들이 정상적으로 전송이 되었다. 성능 관리 겨우 .. 2016. 4. 24. [간보기 | Kafka] Apache Kafka 개요 - 2 Distributiontopic의 partition들은 Kafka 클러스터를 구성하는 서버들에 분산 저장이 된다. partition들은 내고장성을 위해 여러 서버에 복제되며 복제되는 서버의 수를 설정 할 수 있다. 각 partition은 1대의 leader 서버와 0대 이상의 follower 서버들로 구성된다.(즉, leader 서버 1대로도 Kafka 사용이 가능하다.)leader는 읽기 쓰기가 모두 가능하고 follower들은 leader의 데이터를 복제한다. 만일 leader가 고장나면 follower 중 한 대를 leader로 선출한다. 이런 구조로 클러스터 내에서의 부하가 적절히 분산된다. 지난 포스팅 (Apache kafka 시작하기)에서의 기억을 더듬어보면 일단 클러스터 내의 복제 서버는 총.. 2016. 3. 27. [간보기 | Kafka] Apache Kafka 개요 - 1 Apache Kafka 개요지난 글에서 kafka설치 및 설정, 그리고 서버 기동과 간단한 테스트를 진행해 보았다. 오늘은 kafka의 소개 내용을 간단하게 요약해보겠다. 이미 많은 블로그에 원문에 대한 번역에서부터 심층 분석까지 다양한 자료들이 포스팅 되어있으니 나는 그냥 개요만 짚어보련다~ kafka 공식 홈페이지의 indroduction을 보면 다음과 같은 내용으로 시작한다.Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design. 뭐 거의 동어 반복이다. 로그 저장에 대한 분산과 분할과 복제. 그.. 2016. 3. 26. [간보기 | Kafka] 3년만에 찾은 솔루션 kafka...ㅠ.ㅠ 이제야 발견한 Kafka하던 일도 제대로 못하면서 빅데이터 공부해보겠다고 꼴깝을 떤 것이 벌써 2013년 5월달 이야기네… 뭔가 새로운 것에 대해서는 남들 앞에서 한 마디나마 거들 수 있어야 하지 않을까 하는 밑도 끝도 없는 초조감이 나를 뻘짓거리의 함정으로 이끌었다. 뭔가를 시작하기 전에는 지름신을 영접하는 것이 당연한(?) 의례인지라 이 때도 지름신을 조금 과하게(…ㅠ.ㅠ) 영접했다. 맥미니 5대… 그리고는 한 동안은 신났다. Hadoop 설치하고 zookeeper 설치하고 Hbase 설치하고… 그리고…샘플 한 번 돌려보고? 끝이었나?…ㅠ.ㅠ 목표로 삼았던 것이 twitter의 데이터를 수집해서 이것 저것 분석하는 공부를 좀 해보고자 했는데… 이게 당최 감이 안잡히는 것이다. twitter API를 .. 2016. 3. 20. 이전 1 다음 반응형